Reduce LLM & Inference Costs Up to 97%
2-Minute Setup.
Zero markup. Use YOUR API keys from OpenAI, Anthropic, Google, and more. We add intelligent routing and semantic caching—you pay providers directly and keep all savings.
14-day free trial for paid plans. No credit card required. Cancel anytime.
Up to 97%
Cost Reduction
<20ms
Gateway Overhead (p50)
8
AI Providers Supported
114+
Models With Full Scoring
USE YOUR EXISTING API KEYS FROM ALL MAJOR PROVIDERS





Bring Your Own Keys. Keep Control.
Unlike API resellers who add markup fees, Costbase uses YOUR API keys directly. We add intelligence - you keep control.
- Direct billing - pay providers directly
- Your rate limits stay intact
- Enterprise discounts? Keep them.
- Your data privacy agreements apply
- Zero per-token markup fees
How it works:
Configure your provider API keys in Costbase
Point your OpenAI SDK to Costbase gateway
We route intelligently using YOUR keys
Real Test: 96.8% Cost Reduction
Every request analyzed. Every dollar optimized. Here's the proof.
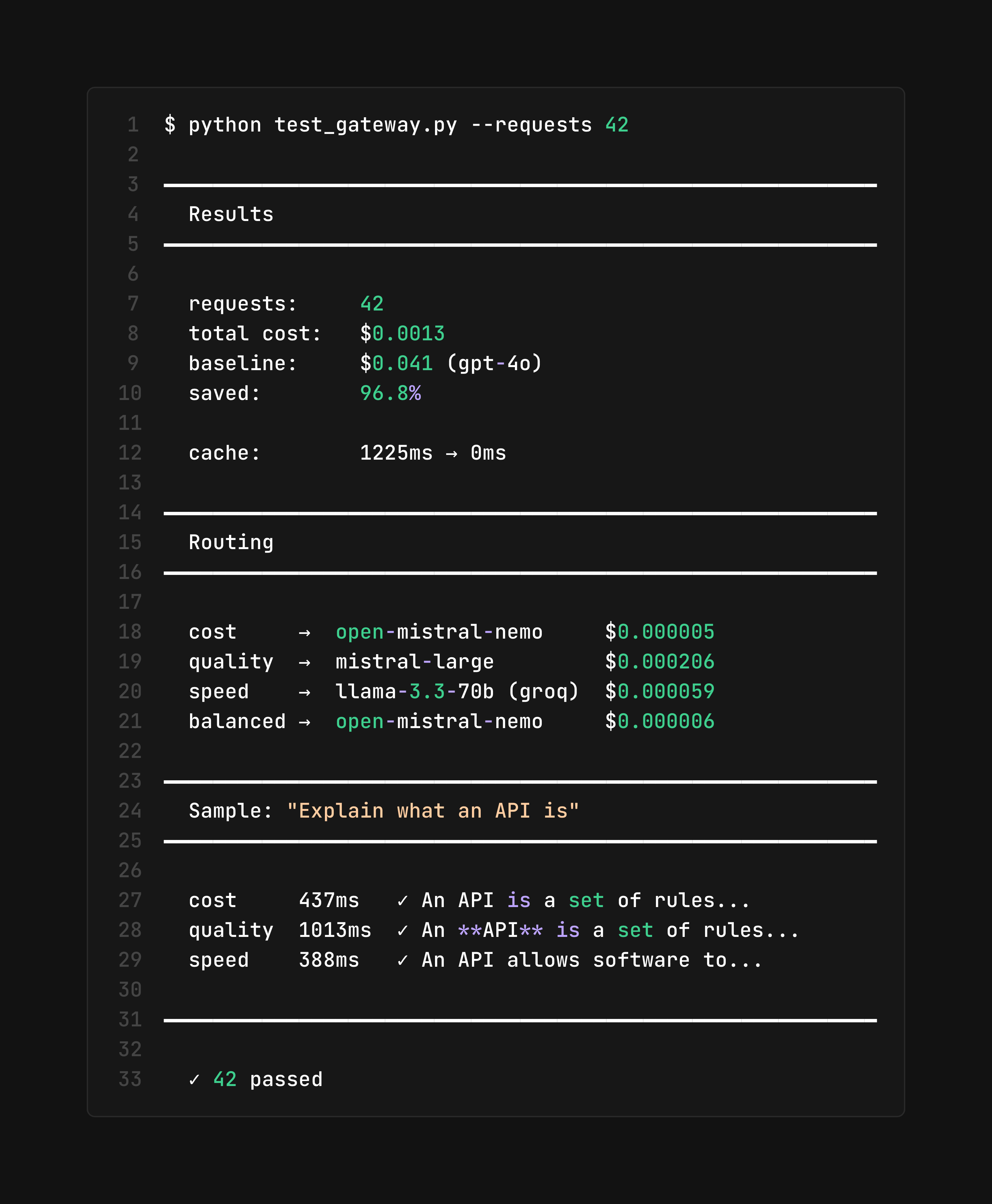
Query: "Explain what an API is"
96.8% Saved
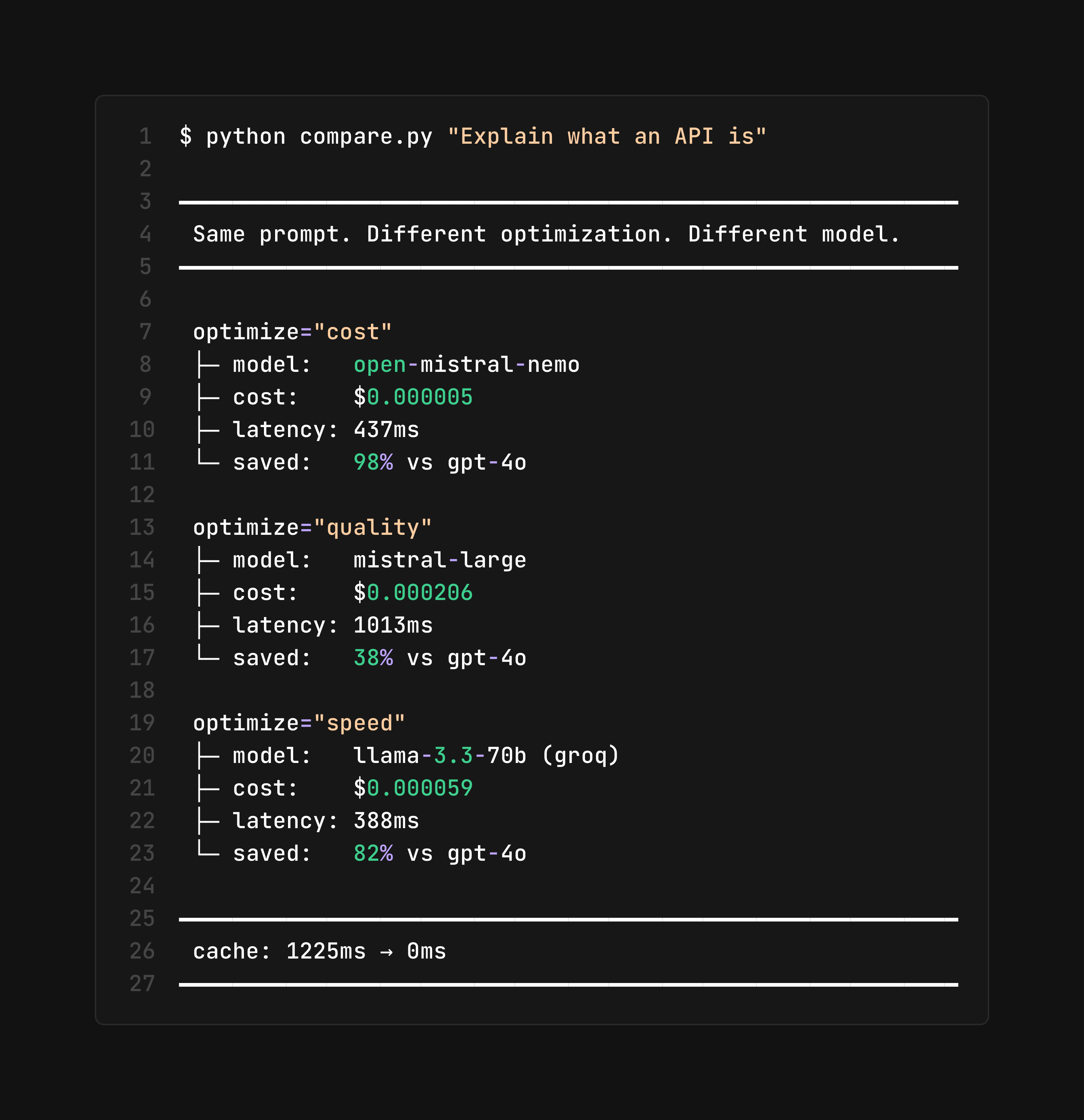
Three Strategies. One Result.
42 requests analyzed with the same prompt. Three different optimization strategies tested. All saved massively vs GPT-4o baseline.
Routed to open-mistral-nemo • $0.000005/request
Routed to mistral-large • $0.000206/request
Routed to llama-3.3-70b (groq) • $0.000059/request
Similar queries return instantly at near-zero cost
Baseline: $0.041 (GPT-4o) • Best result: $0.0013 • You save: $0.0397 per request
See Every Decision. Every Saving.
Your App
OpenAI SDK
Processing in <20ms
Guardrails
PII/PHI check
Budget
Limit check
Cache
Semantic lookup
Smart Route
Best model
Load Balance
Distribute
Failover
<100ms
AI Providers
Your keys
Response
Optimized
Simple Query
"What's the capital of France?"
94% saved
Same quality, fraction of the cost
Complex Analysis
"Analyze Q3 financial trends..."
Savings compound
Cache hit rate improves over time
Four Routing Strategies Working Together
Right model. Right cost. Every time.
Complexity
Scores prompts 0.0-1.0 using length, keywords & patterns. Simple queries → budget models, complex reasoning → flagship models
Task Detection
Identifies task type—coding, creative, analysis, math, translation—and routes to models with matching capabilities
Cost Optimization
Selects the cheapest model that meets complexity & task requirements. No overpaying for simple queries
Performance
Real-time health tracking with circuit breakers, P95 latency monitoring, and automatic failover
Cost intelligence, not cost cutting
Drop-in replacement for OpenAI SDK. Just change the base URL and let intelligence take over.
Intelligent Routing
Three routing strategies (cost, semantic, performance) analyze every request and pick the optimal model automatically.
Learn moreSemantic Caching
AI-powered caching understands query intent. "What is ML?" and "Explain machine learning" return cached results.
Learn moreCost Tracking
Track and attribute LLM costs to customers, users, projects, or teams. Perfect for SaaS billing.
Learn moreAutomatic Failover
Seamless fallback between providers. Never miss a request due to rate limits or outages.
Learn moreBudget Controls
Set limits per API key. Get alerts before overages. Prove ROI to finance with predictive forecasting.
Learn morePII/PHI Protection
Automatically detect and mask sensitive patient and personal data before it reaches AI models—keeping your organization compliant and your users protected.
Social Security Numbers
Detect & mask SSN patterns
Credit Card Numbers
Automatic masking
Medical Record Numbers
PHI protection
Email & Phone Numbers
PII redaction
Custom Patterns
Enterprise-only
// User prompt
"Process payment for patient John Smith,
SSN: 123-45-6789
, card
4532-1234-5678-9010
"
// Sent to LLM (masked)
"Process payment for patient John Smith, SSN: ***-**-****, card ****-****-****-****"
2
Patterns
<5ms
Scan Time
Masked
Action
Available on
Team+ Tier
Healthcare
PHI detection & masking
Finance
Credit card masking
Legal
Client data protection
Government
Sensitive data protection
Built for Production
Real-time monitoring, alerting, and governance for mission-critical AI workloads
Webhooks & Alerts
Send real-time alerts to Slack, Discord, or custom endpoints for budget, rate limits, and SLO violations.
Rate Limiting
Protect your API keys with per-key request limits and sliding window enforcement.
Team Management
Role-based access control for organizations with granular permissions.
See Everything. Control Everything.
Production-grade analytics dashboard with real-time monitoring and detailed breakdowns
Usage Analytics
/usage
Total Requests
127.4K
Cache Hit Rate
23.8%
✓ Cost breakdown by provider, model, and API key
Activity Logs
/activity
2.1K tokens • $0.052
1.8K tokens • $0.054
843 tokens • $0.001
✓ Complete audit trail with request/response inspection
Budget Tracking
/budgets
Daily Burn Rate
$41.57
Projected Spend
$1,746
✓ Predictive forecasting with alerts at 50%, 80%, 100%
SLO Dashboard
/slo
Uptime
99.97%
Target: 99.9%
✓ MEETS SLA
P95 Latency
487ms
Target: <2000ms
Error Rate
0.03%
Target: <0.1%
✓ Real-time violation alerts with historical trends
Plus: Rate Limiting, Team Management, Webhooks, API Keys, Provider Configuration, and more
Start FreeGet started in 2 minutes
No SDK changes. No code refactoring. Just point your existing OpenAI client to Costbase.
Create API Key
Sign up and generate your Costbase API key from the dashboard.
Change Base URL
Update your OpenAI SDK base URL to point to Costbase gateway.
Watch Savings Grow
Intelligence kicks in immediately. Track savings in real-time.
import OpenAI from 'openai';
// Just change the baseURL - intelligence takes over
const client = new OpenAI({
apiKey: 'YOUR_COSTBASE_API_KEY',
baseURL: 'https://api.costbase.ai/v1',
});
// Set model: "auto" for intelligent routing
const response = await client.chat.completions.create({
model: 'auto', // We pick the optimal model
messages: [{ role: 'user', content: 'Explain quantum computing' }],
optimize: 'cost', // Cost, quality, or speed
});
// Response includes cost transparency
console.log(response.costbase);
// → { model_used: "claude-3-haiku", saved_vs_baseline: "$0.041" }Calculate Your Savings
See how much you could save with intelligent routing and semantic caching
Routing Optimization
40% average savings
-$2,000/month
Semantic Caching
20% average savings
-$1,000/month
Annual savings: $36,000
That's 60% reduction in your LLM costs
Stop Overpaying for LLM APIs
Most teams overpay because they use expensive models for every query, can't cache effectively, and have no visibility into spend.
Costbase fixes all of this. Choose your deployment.
Managed Cloud
Fastest way to start
- 14-day free trial on any plan
- No infrastructure to manage
- Automatic updates & scaling
- Enterprise-grade security
Self-Hosted
One-click Terraform deploy
- Production-ready Terraform configs
- Complete data sovereignty
- VPC & on-premise options
- Dedicated support & SLA